반응형
RAID
RAID (Redundant Array of Independent/Inexpensive Disks, 복수 배열 독립 디스크)
- 여러 개의 디스크를 하나의 대용량 디스크처럼 사용, 관리할 수 있는 방식
- 데이터를 동시에 여러 디스크에 저장하여 안정성(신뢰성) 향상과 가용성 확보가 가능
- 디스크 I/O 병렬화로 성능(속도) 향상 가능
- RAID 레벨
- 기본적인 구성 방식은 총 7가지가 존재(Linear RAID, RAID 0~5)
- Linear RAID, RAID 0, RAID 1과 같은 기본 구성
- RAID 5, RAID 6(RAID 5의 변형), RAID 1+0 등이 주로 사용됨

RAID 5

- RAID (여러 개의 디스크를 하나의 디스크처럼 관리)
- 안정성 향상 : 미러링 또는 패리티
- 성능 (I/O속도) 향상 : 스트라이핑
| 구분 | 단일 볼륨 구성 | RAID 0 | RAID 1 | RAID 5 | RAID 1+0(10) |
| 요구 디스크 수 | - | 2개 이상 | 2개 이상 | 최소 3개 이상 | 최소 4개 이상 |
| 읽기 속도 | 보통 | 빠름 | 단일과 같거나 빠름 | 빠름 | 빠름 |
| 쓰기 속도 | 보통 | 빠름 | 단일과 같거나 느림 | 쓰기 속도 느림 (패리티 정보 연산 ) |
빠름 |
| 저장 공간 효율 | 1 | N | 1/N (절반) | (N-1)/N | 1/N (절반) |
| 손실 디스크 허용 | 불가(복구 불가) | 1개 허용 | 1개 허용 | RAID 1당 1개 허용 | |
| 내용 | - | 스트라이핑 (병렬로 쓰기) |
미러링 (복제하기) ※백업이 아님 |
패리티 정보 사용 스트라이핑 | RAID 1로 구성 후 여러 RAID 1를 RAID 0으로 구성 |
Storage
Storage 서비스
- 시공간 제약 없이 데이터를 저장하고 효율적으로 활용할 수 있는 저장소
- 높은 수준의 성능 보장
- 서비스 특성에 따라 최적화된 스토리지 인프라
- 데이터 유실 걱정 없는 백업 정책
스토리지별 저장 방식 – Block Storage
- 데이터를 일정한 크기의 덩어리로 나누어 저장하는 방식
- 서버에 탈부착이 가능하며, 서버를 반납하더라도 블록 스토리지에 저장된 데이터는 남아있음
- 각 블록마다 고유한 주소를 가지고 있어 신속한 검색이 가능
- 정형화된 데이터 처리에 사용

스토리지별 저장 방식 – File Storage
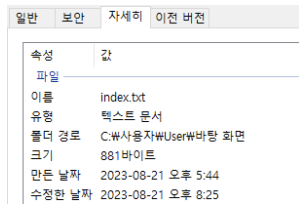

- 파일과 폴더(디렉토리)의 계층구조 방식
- 한정적인 메타 데이터 사용
- 데이터가 많이 저장될 수록 성능이 저하됨
- 네트워크로 접근을 하기 때문에 다수가 접근할 경우 속도 저하
- 메타데이터 : 데이터를 설명하기 위한 데이터, 데이터에 대한 빠른 검색 및 분석이 목적
스토리지별 저장 방식 – Object Storage

- 객체라는 개별 데이터 단위로 데이터를 저장
- 어플리케이션 단에서 동작하여 물리적인 제약이 없음
- 평면(flat) 구조로 데이터를 저장
- 네이버 클라우드 플랫폼 제공 객체 저장소
- Object Storage
- 평면 구조로 데이터 접근이 빠르고 확장성이 좋음
- 고유 식별자와 메타데이터를 통해 객체 검색이 쉬움
- 객체는 HTTPS와 같은 웹, API 등을 통해 접근이 가능
- 저장된 객체를 수정 할 수 없고 덮어쓰기 방식으로 변경됨
- 수정이 자주 일어나는 파일에는 부적합
- 비정형 데이터(동영상, 이미지) 등에 사용
• Block Storage 기능
- 서버에 직접 붙여 쓰는 스토리지 (서버에 마운트해서 사용)
- 특징
- 볼륨 타입은 HDD / SSD 두 가지 타입 제공
- 기본 스토리지 (OS 영역)의 경우 리눅스는 50GB / 윈도우는 100GB로 고정 (※ VPC G2)
- 추가 스토리지 용량은 10GB ~ 2TB(2,000GB) 까지 생성 가능
- 2,000GB 이상의 볼륨 필요할 경우 리눅스는 LVM, 윈도우는 동적 디스크 할당을 사용
- 서버 최대 16개(기본 1개 + 추가 15개)의 스토리지 장착(attach) 가능
- 스토리지 탈착 기능 제공하여 기존 스토리지를 다른 VM에 연결 가능 (탈착과 부착)
- 추가 스토리지 사이즈 증가 기능 제공 (축소 불가)
- 스토리지 Live snapshot 가능
- Zone이 다르면 스토리지를 사용할 수 없음 (스냅샷을 통해 다시 생성)
- IOPS (초콜릿 조각을 초당 얼마까지 먹을 수 있는가?)
- SSD 타입에 한해 1GB 당 40 IOPS 보장
- 최소 4,000 IOPS 보장 (10GB ~ 100GB 크기의 경우 4,000 IOPS 제공, 이후 1GB 당 40 IOPS 증가)
- 최대 20,000 IOPS 보장 (1,000GB 를 생성하더라도 최대 20,000 IOPS까지만 보장)
Object Storage (모든 종류의 데이터를 인터넷 상에 저장 및 검색 가능한 객체 스토리지)
- AWS S3(Simple Storage Service)와 같은 오브젝트 단위 무제한 용량 파일 저장 스토리지
- 비정형 데이터를 안전하게 저장하고 관리하기 위한 스토리지
- Object Storage 특징
- 데이터 암호화 및 여러 단계의 보안 장비를 통한 데이터 무결성 및 복원력 보장
- 고유 식별자와 메타 데이터를 통한 저장된 데이터의 빠른 검색
- 초대용량 데이터 저장 가능
- Object Storage 기능
- AWS S3와 호환되는 API를 제공하며, S3와 관련된 3 rd party 솔루션 사용 가능
- 다양한 도구를 통해 관리 가능 (콘솔, RESTful API, SDK, CLI를 통해서 파일 관리)
- 각 파일마다 고유한 접근 URL이 부여되며, 해당 URL을 통해 인터넷 상에서 쉽게 접근 가능
- 버킷 단위, 오브젝트 단위의 접근 권한 설정 기능 제공
- CDN+ 서비스, CLA 로그 저장, media 서비스 등 NAVER CLOUD PLATFORM에서 제공하는 상품과 연동 가능
- Sub Account를 통해 접근 권한 관리 기능 제공
- 사용 사례
- 정적 컨텐츠 (동영상, 사진 등)을 저장 및 배포 용도
- 빅데이터 분석 시 대량 데이터를 저장 및 보관
- 클라우드 기반 애플리케이션 개발 시 데이터 저장소로 사용
- 백업용 데이터 보관
Archive Storage (데이터 아카이빙 및 장기 백업에 최적화된 스토리지)
- AWS S3 Glacier에 대응되는 상품
- Cold 데이터 보관 및 백업 아카이빙 데이터 저장이 주목적
- 저장 비용 : Object Storage 대비 저렴
- API 요청 비용 : Object Storage 대비 비쌈
- Archive Storage 기능
- 스토리지 관리 기능과 인터페이스 제공 (웹 콘솔 및 Swift API를 제공)
- S3 SDK 라이브러리 일부 호환 지원 (Swift API 외 S3 API 일부 제공)
- Sub Account를 통해 접근 권한 관리 기능 제공
- 사용 사례
- 의료 정보, 제조 정보 관리, 금융 거래 내역 등 컴플라이언스 준수를 위해 장기 보관 저장소가 필요한 경우
- Object Storage에 사용 빈도가 높은 데이터를 저장하고, Archive Storage에 사용 빈도가 낮은 데이터를 저장
NAS
- 네트워크로 연결하는 저장 공간으로 다수의 서버가 공유할 수 있는 스토리지
- 최소 500GB에서 최대 10,000GB까지 생성 가능 / 100GB 단위로 용량 증가
NAS의 특징
- NFS(Linux) / CIFS(Windows) 프로토콜 제공
- Live resizing 가능
- 스냅샷 기능 : 스케줄 기반으로 백업 목적의 스냅샷 생성 가능
- NAS에 할당된 용량 중 일정 부분을 스냅샷 공간으로 사용함
- 스냅샷은 최대 7개 보관 (초과 시 오래된 스냅샷부터 삭제됨)
- 자동 생성과 즉시 생성이 가능함
- 즉시 생성으로 생성한 스냅샷은 용량이 허용되는 한도 내에서 제한 없이 보관
- 모니터링 기능 제공 (사용량 %)
- 접근 제어 기능
- NFS : IP로 접근 제어
- CIFS : ID와 패스워드로 접근 제어
Backup
- Linux, Windows 계열 지원 – 파일 시스템 백업
- 각종 데이터베이스(MSSQL, MySQL, PostgreSQL)의 온라인 백업 가능 – 데이터베이스 백업
- 간편하게 서버에 Agent를 설치 후 백업 정책 구성을 웹 콘솔 상에서 가능
- 증분 백업, 소산 백업 기능 제공
- 백업된 데이터는 최대 365일까지 보관 가능 (보관 기간 설정 가능)
- 백업 수행 주기 : 일간, 주간, 월간, 일회성
- 백업 데이터 보관 기간 : 7일 ~ 364일(52주) 기간 내 설정 (※ 백업 수행 주기 기준 최소 2배 이상 설정)
- 총 백업 용량은 최소 100GB에서 수 십 TB까지 (단일 서버 하루 백업 최대 용량 1TB)
| 구분 | Block Storage | Object Storage | NAS |
| 타입 및 특징 | 블록 스토리지 | 객체 저장소 | 네트워크 공유 스토리 |
| 저장 요금 | HDD : 저렴 SSD : 가장 비쌈 |
가장 저렴 | HDD < NAS < SSD |
| 용도 | HDD : 대용량 데이터 SDD : 속도가 중요할 때 |
대용량 데이터 보관 및 웹을 통한 컨텐츠 공유 |
연결된 서버 간 데이터 공유 |
| 제약 | 10GB 씩 증가 10GB ~ 2,000GB 추가 가능한 스토리지 15개 |
PB 단위까지 확장 가능 (업로드 API 가능 단일 파일 10TB 이하) (웹콘솔 업/다운 2GB 이하) |
100GB 단위로 증가 500GB ~ 10,000GB |
| 사용법 | 서버에 마운트 | 도구(웹 콘솔, CLI, API 등) 또는 프로그래밍 방식 |
서버에 마운트 (NFS, CIFS) |
| 사례 | 웹 서버 데이터 베이스 데이터 웨어하우스 |
데이터 레이크 데이터의 수명에 따른 아카이빙 백업, 로그 등 장기 저장 용도 미디어(동영상, 이미지) 저장, 전달 |
서버간 컨텐츠 공유 |
실습


반응형
'배운 내용 > 클라우드 교육' 카테고리의 다른 글
| 네이버 클라우드 실습1 - 서버 만들기 (0) | 2023.10.12 |
|---|---|
| 10월12일(목) Database (0) | 2023.10.12 |
| 10월10일(화) Compute&Network (2) | 2023.10.11 |
| 10월6일(금) 클라우드를 위한 기초 이론 (2) (1) | 2023.10.10 |
| 10월5일(목) 클라우드를 위한 기초 이론 (1) (1) | 2023.10.05 |
