Image Quality Assessment는 잘 모르는 분야이기 때문에 논문을 읽고 모델을 찾아야 한다.
논문 읽는 것이 쉽지 않지만 그래도 최대한 이해하려고 노력하며 읽어봤다.
논문 이해도 60% + 뇌피셜 40%
1. Introduction
- 목표
-
사람이 보는 것과 유사하게 image quality를 판단하는 모델을 만들자.
-
- 기존의 모델은 Synthetically distorted image(인위적으로 왜곡된 이미지)에 대한 평가는 잘한다.
-
실제로는 No-Reference Image Quality Assessment(NR-IQA)가 중요하다.
- 우리가 접하는 대부분의 이미지는 Authentically distorted image(자연적으로 왜곡된 이미지)이기 때문이다.
-
NR-IQA가 어려운 이유
-
부분적인 distortion이 많다.
-
기존의 모델은 classification과 image quality를 같이 판단한다.(이 논문의 핵심 내용)
-
2. Related Work
2.1. IQA for Synthetically Distorted Images
- hand-crafted feature based IQA
-
require expertly design and are time-consuming
- (전문가가 직접 만든 모델, 만들기 어렵고 시간이 오래 걸린다.)
-
Global view에서만 image quality를 측정
- (이미지 전체를 보고 quality를 측정한다. local distortion을 찾지 못함.)
-
-
learning feature based IQA
-
CNN 이용해서 성능이 좋아짐.
-
synthetic databases에만 성능이 좋다.
-
content variation, diverse distortion types 고려 안함.
- (왜곡의 종류, 이미지의 특징에 대해 고려하지 않는다.
- 예를 들어, 하늘과 청바지의 경우 모델은 이 둘을 잘 구별하지 못한다.)
-
2.2. IQA for Authentically Distorted Images
- semantic features가 image quality에 영향을 주는 것처럼 보인다.
- (모델 성능이 좋아질 수록 classification을 잘하고, image quality도 잘 예측한다.)
-
최근 모델은 semantic features를 quality prediction에 사용한다.
-
두 가지 단점이 존재함
-
Image semantics와 quality perception 관계를 고려 안함
-
(예를 들어, 사람은 image content 판단 후 quality를 판단하지만 모델은 동시에 평가한다.)
-
global scale에서 image feature를 정하기 때문에 local distortion을 판단 못함.
-
-
image semantic features are learned first,
- (이 논문에서 소개하는 모델은 어떤 이미지인지 먼저 판단하고,
-
quality is predicted based upon what content the image delivers.
- 이미지 특징에 맞게 quality를 측정한다.)
3. Proposed Method

전체적인 모델 소개
이 모델은 ResNet50을 베이스로 만들어졌다.
크게 3부분으로 나뉘는데, ResNet50 base, Hyper Network, Target Network이다.
ResNet50 base에서는 conv를 통과할 때마다 patch로 나누어 Multi-scale content feature(local feature)를 추출한다.
이후 ResNet50 base 최종 conv에서는 Semantic feature(global feature)를 추출한다.
Hyper Network에서는 ResNet50 base에서 추출한 Semantic feature를 1*1conv를 통해 채널을 줄이고 Reshape와 3*3conv를 통해 weights를 계산하고, FC와 GAP를 통해 Bias를 계산한다.
Hyper Network에서 나온 weights와 bias는 Target Network에 input 된다.
Target Network에서는 ResNet50 base에서 추출한 Multi-scale content feature와 Hyper Network에서 추출한 weights와 bias를 4개의 FC layer를 통과시켜 최종 score를 계산한다.
이 모델에서 중요한 부분은
ResNet50 base에서 Multi-scale content feature(local feature)를 추출하는 부분과
Hyper Network에서 나온 weights와 bias이다.
이 3가지 값을 이용하여 quality를 측정하기 때문에 다른 모델에 비해 정확도가 올라간다.
3.1. Self-Adaptive IQA Model

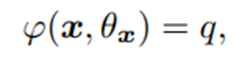
(dependent on the image itself instead of being fixed for all inputs)
논문 저자들이 만든 모델의 경우
- x에 이미지를 넣고 학습시키면 Θx가 x에 따라 변동되기 때문에 이미지에 따른 quality를 판단하기 용이하다.
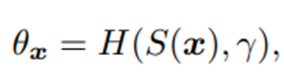
Θx는 hyper network mapping function(저자들이 만든 함수)에 γ와 S(x)를 넣어서 계산한다.
γ는 hyper network parameters이고 S(x)는 이미지 전체의 feature(global feature)이다.
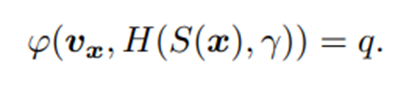
3.2. Semantic Feature Extraction Network

ResNet50 base에서는 conv를 통과할 때마다 patch로 나누어 Multi-scale content feature(local feature)를 추출한다.
3.3. Hyper Network for Learning Perception Rule

Hyper Network에서는 ResNet50 base에서 추출한 Semantic feature를 1*1conv를 통해 채널을 줄이고 Reshape와 3*3conv를 통해 weights를 계산하고, FC와 GAP를 통해 Bias를 계산한다.
Hyper Network에서 나온 weights와 bias는 Target Network에 input 된다.
3.4. Target Network for Quality Prediction

Target Network에서는 ResNet50 base에서 추출한 Multi-scale content feature와 Hyper Network에서 추출한 weights와 bias를 4개의 FC layer를 통과시켜 최종 score를 계산한다.
sigmoid 함수가 activation 함수로 쓰인다.
3.5. Implementation Details

4. Experiments
4.1. Datasets
- LIVE Challenge (LIVEC)
- 1162 images
- complex and composite distortions
- KonIQ-10k
- 10073 images
- sense of brightness, colorfulness, contrast and sharpness
- BID
- 586 images
- realistic blur distortions such as motion blur and out of focus
- LIVE and CSIQ
- 779 and 866 synthetically distorted images
dataset에 대해 다 다루기는 어려워 KonIQ-10k만 알아보았다.
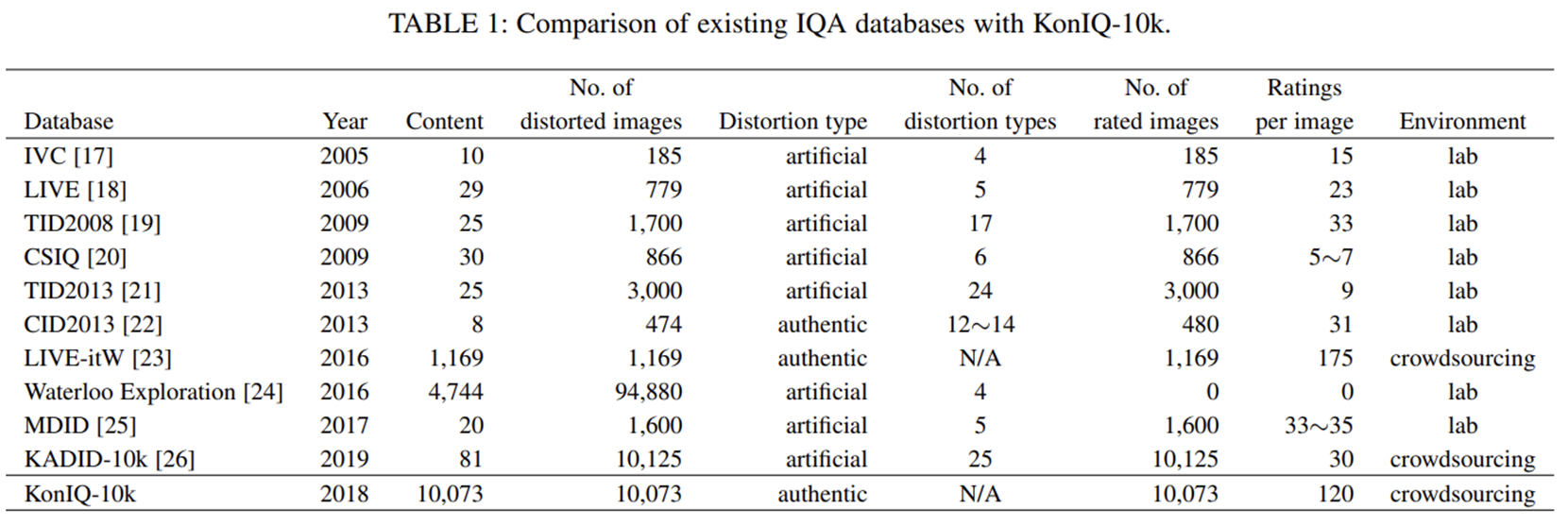
다른 dataset에 비해 이미지 수가 매우 많고 왜곡 종류도 많다.
또한 자연적으로 왜곡된 이미지들이기 때문에 local distortion이 많다.

대충 보면 일상 생활에서 볼 수 있는 이미지들이 많다.


이미지와 함께 2개의 csv파일이 있는데 이미지에 대한 정보가 담겨있다.
이 많은 정보들 중 모델은 어떤 것을 정답으로 쓰나 코드를 확인해보았다.

코드를 보면 MOS_zscore를 쓴다는 것을 알 수 있다.
MOS_zscore는 MOS에 ACR value를 계산한 값으로 잘 모르겠다.
MOS와 그냥 비슷하다고 생각한다.
ACR value는 사람이 이미지를 보고 어떤 이미지인지 얼마나 잘 인지하는지 나타낸 것이다.(사실 잘 모른다.)
4.2. Evaluation Metrics
- Spearman’s rank order correlation coefficient (SRCC)
- Pearson’s linear correlation coefficient (PLCC)
- 이 모델은 평가 지표로 SRCC와 PLCC를 사용하였다.
- PLCC와 SRCC는 간단히 설명하면 x와 y 사이에 어떤 상관관계가 있는지 나타낸 것이다.
- 0이면 상관관계가 없는 것이고 1에 가까울 수록 양의 상관관계를 갖는다.(x가 커지면 y가 커진다.)

코드를 보면 마지막에 PLCC와 SRCC를 계산하고 값을 return 한다.
4.3. Comparison with the State-of-the-art Methods


다른 모델과 비교하면 Synthetic distortion dataset인 LIVE와 CSIQ를 제외하고 최고 점수가 나온다.
이 모델이 Synthetic distortion에 특화된 모델이 아님에도 LIVE와 CSIQ dataset에서 준수한 점수가 나온다고 설명하고 있다.

Training dataset과 Testing dataset을 바꾸어 보아도 좋은 점수가 나온다.

4.3. Comparison with the State-of-the-art Methods

gMAD competition은 두 개의 모델을 attacker와 defender로 나누어 비교를 하는 것이다.
여기서는 논문 모델과 GM-LOG, DBCNN 모델을 비교하였다.
Fixed 되어 있는 모델이 defender이다.
간단히 설명하면 attacker가 하나의 이미지를 선정한다.
defender는 그 이미지 quality와 비슷한 이미지를 선택하여 제시하는 것이다.
첫번째 그림을 보면 GM-LOG가 quality가 낮은 이미지를 선택하였고, 논문 모델 역시 quality가 낮은 이미지를 선택하였다.
두번째 그림에서는 GM-LOG가 quality가 높은 이미지를 선택하였고, 논문 모델 역시 quality가 높은 이미지를 선택하였다.
세번째 그림에서는 attacker와 defender가 바뀌어 있다.
세번째 그림에서는 논문 모델이 quality가 높은 이미지를 선택하였지만 GM-LOG는 quality가 낮은 이미지를 선택하였다.
이 competition을 통해 논문 모델이 quality가 비슷한 이미지를 찾는데 뛰어나다는 것을 알 수 있다.
4.4. Visualization of Self-Adaptive Weights

이 그래프를 보면 target network의 첫번째 layer에 들어가는 weights를 점으로 나타낸 것이다.
빨간점과 주황점을 보면 이미지는 모두 '개' 이지만 quality가 다르다는 것을 알 수 있다.
하지만 두 점은 매우 가깝게 위치함으로써 이 모델이 quality를 판단하기 전에 이미지의 feature를 먼저 판단한다는 것을 알 수 있다.
보라색 점과 녹색 점 역시 두 이미지 모두 '항아리'이고 quality가 다르지만 feature를 나타내는 점은 비슷한 곳에 있다는 것을 알 수 있다.
하늘색 점과 파란색 점은 두 이미지의 quality가 모두 좋지만 '구름'과 '눈 발자국'으로 feature가 다르기 때문에 점이 멀리 위치한 것을 볼 수 있다.
4.5. Ablation Study
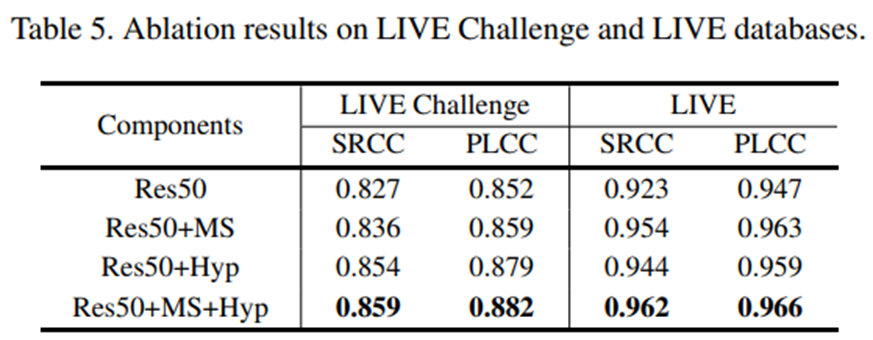
모델의 components를 제거했을 때의 점수를 나타낸 것으로 모든 components가 있어야 점수가 제일 좋다는 것을 보여준다.
5. Conclusion
- 기존의 모델이 image feature와 image quality를 함께 고려할 때,
-
논문에서 소개한 모델은 global image feature를 먼저 고려하고,
-
Local image feature를 image quality를 계산하는데 적용하였다.
-
이러한 특징들로 인해 이 모델은 사람이 image quality를 판단하는 기준과 유사하게 판단할 수 있다.
- 즉, MOS 값을 예측하는데 좋은 성능을 보인다.
아이고...
논문 읽는 것 왜이렇게 어렵냐...
설명하는 것도 너무 어렵다.
그동안 구글에서 논문 소개하는 블로그들 많이 봤는데, 정말 대단한 것 같다.
'프로젝트 > No Reference Image Quality Assessment' 카테고리의 다른 글
| NR-IQA를 활용한 Face Image Quality Assessment (0) | 2022.10.27 |
|---|---|
| 현재까지 진행 사항 (0) | 2022.09.27 |
| No-Reference Image Quality Assessment와 Full-Reference Image Quality Assessment 차이 (0) | 2022.09.14 |
| 프로젝트 시작 (0) | 2022.09.14 |
