1. Introduction
기존의 NR-IQA는 이미지 전체의 품질을 판단하기 때문에 사람의 얼굴만의 품질을 판단하기에는 적합하지 않다. 또한, 기존의 FIQA는 대부분 Full Refence 기반으로 만들어지기 때문에 Refence가 없는 경우 model을 train하는 것이 불가능하다. 따라서 이번 프로젝트에서는 NR-IQA를 이용하여 NR-FIQA model을 만들어 보고자 한다. 사용한 모델은 NR-IQA model 2가지(MANIQA, MUSIQ), FIQA model 2가지(SDD-FIQA, MagFace)이며 사용한 dataset은 KonIQ-10k, Tid2013, 한국인 안면 데이터(ai hub), FFHQ이다. 먼저 NR-IQA와 FIQA model의 code를 분석하여 각 model의 적용 원리를 이해하고 NR-IQA model 중 하나, FIQA model 중 하나를 선택하여 두 mdoel을 접목시키도록 한다.
2. Related Work
2-1. Multi-dimension Attention Network for No-Reference Image Quality Assessment(MANIQA)

MANIQA model의 가장 큰 특징은 Vision Transformer를 이용한다는 점과 Position Embedding을 통해 local interaction을 찾는다는 점이다. 기존의 NR-IQA model과 달리 이미지의 local interaction을 ViT에 input함으로써 이미지를 patch로 잘랐을 때 patch 간 interaction을 model이 학습하게 함으로써 더 정확한 score를 예측하도록 한다.
2-2. Multi-scale Image Quality Transformer(MUSIQ)

MUSIQ model의 가장 큰 특징은 Conv layer를 통과하는 과정에서 이미지의 비율을 그대로 유지한다는 점이다. 기존의 IQA 방식은 conv layer를 통과하며 이미지의 크기가 작아지고 비율이 달라지기 때문에 기존의 이미지와 다른 이미지를 학습하는 것과 비슷한 영향을 주게 된다. MUSIQ의 경우 이미지를 resizing하지만 patch로 자르고 resizing하는 과정에서 각 patch마다의 이미지 비율을 유지하기 때문에 conv layer를 통과한 이후에도 원본 이미지와 같은 비율을 유지하며 resizing된 patch의 feature도 patch encodong module을 통해 Transformer에 전달하기 때문에 원본에 가까운 이미지 feature로 학습을 할 수 있게 된다.
2-3. SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance

SDD-FIQA model의 특징은 intra-class와 inter-class 사이의 Wasserstein distance를 계산하여 이미지를 class 별로 나누어 학습하는 것이다. 기존의 FIQA의 경우 input된 이미지를 각각으로 나누어 feature를 찾기 때문에 유사한 이미지 사이의 상관관계 또는 유사하지 않은 이미지 사이의 상관관계에 대해 큰 의미를 두지 않았다. 하지만, SDD-FIQA model의 경우 이미지를 class 별로 나누어 input하기 때문에 model이 class에 따른 feature 차이를 학습할 수 있고, class내의 이미지에 대해 공통적인 feature를 학습함으로써 face에 대한 feature를 더 자세히 학습할 수 있다. 또한 단순한 거리를 구하는 Euclidean Distance를 쓰는 것이 아니라 class 간 거리를 구할 수 있는 Wasserstein distance를 사용하기 때문에 class 내의 feature 차이를 더 잘 구분할 수 있다. SDD-FIQA model의 또다른 특징은 Pseudo-label을 만든다는 점이다. Pseudo-label은 class 내 feature와 class 외 feature를 이용하여 계산하고 이 Pseudo-label을 사용해 Train할 때의 MOS값을 대신한다.
2-4. MagFace: A Universal Representation for Face Recognition and Quality Assessment
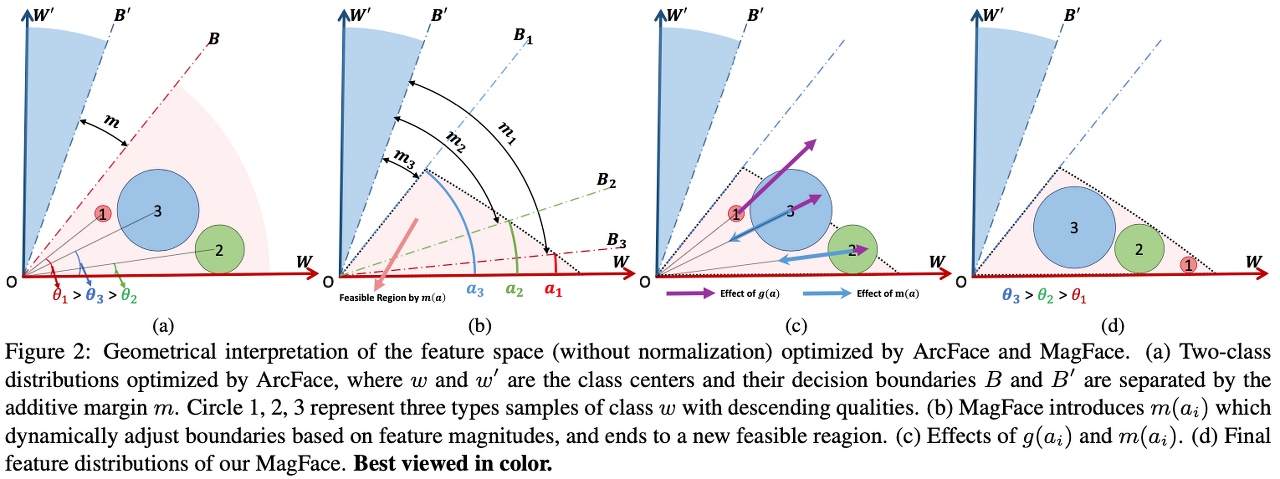
MagFace model은 ArcFace model을 기반으로 cos θ값을 이용해 이미지 간의 feature 차이를 학습한다. 하지만 ArcFace의 경우 단순히 cos θ만을 이용하기 때문에 이미지 quality 차이에 따른 가중치를 줄 수 없는 문제가 있었다. MagFace는 cos θ에 g와 m 이라는 가중치를 새로 부여함으로써 학습 시 이미지 quality에 따라 같은 class 내의 이미지라도 다른 feature 값을 갖게 되기 때문에 이미지 quality를 더 잘 예측할 수 있다.
3. The Proposed Model
3-1. NR-IQA+ SDD-FIQA(Pseudo-label)
NR-IQA model은 train할 때 MOS값을 y값으로 하여 train 해야 한다. 하지만 MOS값은 사람의 주관에 따라 달라지는 값이고 MOS값을 구하기 위해서는 많은 비용과 시간이 필요하다. 따라서 우리는 SDD-FIQA에 있는 Pseudo-label을 사용하여 MOS값을 대신해 보기로 하였다. SDD-FIQA에 있는 Recognition model만 따로 분리하고 train dataset을 넣어 Pseudo-label을 구한 후 이 Pseudo-label을 y값으로 하여 NR-IQA model을 train하였다.
3-2. MagFace + NR-IQA
MagFace는 사람의 얼굴을 detection하는데 특화되어 있는 model이고 NR-IQA model은 Image Quality Assessment에 특화 되어 있는 model이기에 두 model의 결과값을 합친 model을 만들어 보기로 하였다. 특히, MANIQA의 경우 score branch와 weight branch를 통해 score를 계산하기에 두 값에 다양한 변화를 주는 것이 가능할 것이라 생각하였다. MagFace의 score 값을 이용해 MANIQA score에 다양한 변화를 주어 더 나은 score를 예측하도록 계획하였다.
4. Experiments
4-1. NR-IQA model(MANIQA)을 이용해 다양한 dataset의 score를 검증
- model : MANIQA(epoch1)
- dataset : KonIq-10k
- SROCC : 0.22186207395528537
- PLCC : 0.09365801807886241
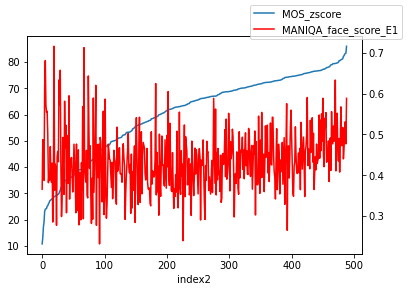
- model : MANIQA(epoch11)
- dataset : KonIq-10k
- SROCC : 0.8706164785279675
- PLCC : 0.8832811101553448

MANIQA의 경우 pretrained model이 없기에 직접 train하였다. epoch 수가 늘어날 수록 좋은 성능을 보인다.
- model : MANIQA
- dataset : FFHQ

다른 NR-IQA model인 HyperIQA를 사용해 점수를 매겼을 때 하위5장의 image를 predict한 결과이다. HyperIQA와 비슷하게 대부분 낮은 점수를 보인다.

다른 NR-IQA model인 HyperIQA를 사용해 점수를 매겼을 때 상위5장의 image를 predict한 결과이다. HyperIQA와 비슷하게 대부분 높은 점수를 보인다.
문제점 : 우리가 사용하고자하는 data는 Face Image 이기 때문에 KonIq-10k와 FFHQ dataset에서 사람이 포함된 이미지만을 사용하였다. 하지만 이 두 dataset에 있는 MOS값은 이미지 전체를 보았을 때 측정한 MOS값이기 때문에 사람의 얼굴 외적인 부분이 MOS값 또는 predict score에 영향을 주었을 가능성이 있다. 이것을 해결하기 위해 얼굴 부분만 crop하여 다시 score를 예측하였으나 매우 좋지 않은 결과를 보여주었다.

해결 방안 : 같은 이미지에 다양한 distortion이 있는 tid2013 dataset을 사용해 보기로 하였다.
- model : MANIQA
- dataset : tid2013
- SROCC : 0.5148255607947497
- PLCC : 0.5547288175220667



tid2013 dataset을 이용하여 예측한 결과 MOS값이 상승하면 score가 상승하는 경향성을 보이기는 하지만, 격차가 너무 커 제대로 예측한다고 할 수 없는 결과를 보여주었다.
4-2. NR-IQA model(MUSIQ)을 이용해 다양한 dataset의 score를 검증
- model : MUSIQ
- dataset : KonIq-10k
- SRCC : 0.873210603
- PLCC : 0.893541570

crop하지 않은 KonIq-10k dataset에 대해서는 좋은 결과를 보이지만, crop한 dataset에 대해서는 좋지 않은 결과를 보인다.

dataset을 바꾸어 다양한 distortion이 있는 tid2013 dataset을 사용하여 score를 예측하였다.
- model : MUSIQ
- dataset : tid2013
- SRCC : 0.6807296806457306
- PLCC : 0.7698597521237569

MANIQA에 비해 더 좋은 경향성을 보인다.
4-3. FIQA model(SDD-FIQA)을 이용해 다양한 dataset의 score를 검증
- model : SDD-FIQA
- dataset : FFHQ


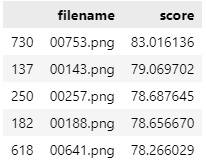

SDD-FIQA의 경우 얼굴의 눈, 코, 입 위치에 따른 영향을 많이 받았다. 또한 안경, 그림자 등 얼굴의 특징을 잡기 어려운 경우 score가 낮게 나오는 경향이 있었다. FFHQ dataset은 고화질로만 이루어진 dataset이기 때문에 점수가 일관적으로 높에 나올 것이라 예상했지만 낮게는 20점, 높게는 83점으로 큰 편차를 보여주었다.
- model : SDD-FIQA
- dataset : AiHub 한국인 안면 데이터


한국인 안면 데이터를 사용하여 score를 예측한 결과, 얼굴 특징에 따른 점수 차이를 명확히 보여준다. 정면을 보는 이미지의 경우 점수가 높게 나오고, 옆면의 경우 점수가 낮게 나오는 경향을 보여주었다.
4-4. FIQA model(MagFace)을 이용해 다양한 dataset의 score를 검증
- model : MagFace
- dataset : FFHQ

MagFace 역시 얼굴의 특징에 따른 점수 차이가 나타났다. 점수가 높은 사진의 경우 밝고 정면은 보는 사진이 많고, 점수가 낮은 사진의 경우 옆면이거나 그림자, 다른 물건 등이 포함된 이미지가 많았다.
- model : MagFace
- dataset : AiHub 한국인 안면 데이터


AiHub 한국인 안면 데이터를 예측한 결과, MagFace의 특징을 정확히 보여준다. 정면 이미지의 경우 점수가 높고, 옆면 이미지의 경우 점수가 낮게 나온다.
4-5. Model Fusion
- MANIQA + MagFace

MANIQA는 score를 예측할 때 Score Branch와 Weight Branch에서 구한 값을 계산하여 최종 score를 예측한다. Score Branch에 MagFace에서 구한 score 값을 적용한다면 조금 더 Face Image Quality에 맞는 score를 예측할 것이라 생각했다.

s = scoring branch
w = weighting branch
q = final score







다양한 연산을 통하여 score를 예측한 결과 [W(weighting branch) X MagFace] 방법이 우리가 목표로 하는 score에 가장 유사하게 나왔다.
5. Conclusion
MOS값을 사용하지 않는 FIQA model을 만들기 위하여 NR-IQA model과 FIQA model을 합친 model을 만들고자 하였다. NR-IQA model은 train하기 위해 MOS값을 y값으로 필요로 하고, FIQA model은 MOS값은 필요로 하지 않지만 dataset이 class 별로 나뉘어 있어야 한다. FIQA model을 통해 image의 feature가 사람의 얼굴인지 판별하고 NR-IQA model을 통해 image의 quality를 판단하여 최종 score를 내도록 하였다. NR-IQA model을 총 5가지 살펴보았지만 성능이 안좋거나 구현이 어렵다는 이유로 MANIQA와 MUSIQ 2가지 모델을 선택하였고 FIQA model과의 fusion을 하는 과정에서 최종적으로 MANIQA를 선택하였다. FIQA model은 총 3가지 model 중 성능 및 구현을 이유로 SDD-FIQA, MagFace를 선택하였고 AiHub dataset을 통해 최종적으로 MagFace를 선택하였다. 각각의 model을 다양한 dataset으로 판단하였을 때 만족할 만한 결과가 나오지 않았지만, 두 model을 fusion한 후 수식을 다양하게 하여 최종 score를 계산한 결과 high, middle, low에 맞게 image가 구분되는 최종 수식을 찾아내었다.
6. Discussion
MOS값을 사용하지 않기 위해 FIQA를 사용하였지만 결국 train을 하기 위해서는 image를 class 별로 나누어야 한다. 이러한 작업 역시 데이터 전처리 과정이 필요하고 crawling 등의 단순한 data 수집으로는 model 학습에 바로 쓰기에는 어려운 문제점이 있다. 또한, NR-IQA model을 학습하기 위해서는 여전히 MOS값을 필요로 한다. 최종 score에서 high quality와 middle quality가 구분이 되기는 하지만 그 차이가 근소하기 때문에 dataset에 따라 score로 구분이 어려울 수 있다.
7. Project review
IQA에 대해 잘 모르기 때문에 많은 논문을 찾아봐야 했다. 논문을 이해하는 과정도 어려웠고 논문에 나와있는 model을 구현하는 과정도 어려웠다. GPU 사용 및 서버 활용에 있어 미숙하기 때문에 다양한 dataset을 train하지 못하였다. 이번 프로젝트 주제가 사람의 얼굴이기 때문에 사람 얼굴만 있는 dataset을 구하는 것이 어려웠고 특히, MOS값이 있는 dataset을 구하는 것이 어려웠다.
그동안 진행했던 교육 과정 및 프로젝트는 단순히 따라하는 과정이 많았기에 model을 구현하는 것에 대해 크게 어려움을 느끼지 못하였다. 하지만 이번 프로젝트는 처음부터 끝까지 스스로 구현을 해야 했기에 많은 부분을 스스로 찾아 문제점을 해결해야 했다. 논문을 읽는 것이 익숙하지 않기에 처음에는 시간이 오래 걸렸지만 읽은 논문의 수가 늘수록 점점 익숙해지기 시작하였고 model 구현 역시 시간이 지날 수록 익숙해졌다.
최대한 기업이 요구하는 방향으로 결과를 도출할 수 있도록 프로젝트 방향을 정하였고 최종 발표 이후 기업 측에서도 만족하는 답변을 해주었기에 뿌듯함을 느낄 수 있는 프로젝트였다.
'프로젝트 > No Reference Image Quality Assessment' 카테고리의 다른 글
| 현재까지 진행 사항 (0) | 2022.09.27 |
|---|---|
| 내 마음대로 논문 읽기[Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network] (0) | 2022.09.14 |
| No-Reference Image Quality Assessment와 Full-Reference Image Quality Assessment 차이 (0) | 2022.09.14 |
| 프로젝트 시작 (0) | 2022.09.14 |
